
Продам свой голос за свитшот
Автор: Алексей Смагин
Дата-история: «Продам свой голос за свитшот»
Материал опубликован на сайте «Новой Газеты» 21 сентября 2018 года
Инструменты: Excel, API, Python (библиотека pandas), Nodebox, Tableau Public, Adobe Illustrator
Источники данных: открытые данные портала «Активный гражданин», соцсети, данные портала «Российская общественная инициатива»
В этом материале я разберу дата-исследование «Продам свой голос за свитшот», которое описывает особенности голосования на портале «Активный гражданин» — это такой сервис электронной демократии в Москве. Горожанам там предлагают голосовать за разные аспекты жизни города, чаще всего малозначимые. Например, пользователи «АГ» выбирают названия новым станциям метро и решают, на каком сайте размещать рейтинги книг из московских библиотек.
Поиск идеи
Идея для этого материала появилась случайно: подруга написала мне, что у платформы скоро день рождения, и это, возможно, повод исследовать её эффективность.

Я решил изучить этот вопрос, и обнаружил, что на портале есть целый раздел с открытыми данными, где публикуются результаты некоторых опросов. Так «Активный гражданин» хочет повысить доверие к своим данным. Доступных наборов данных на апрель 2021 года было 431, правда, опросов на портале было на порядок больше.
Прелесть этих данных в том, что по каждому из раскрытых голосований можно скачать детали, где указан уникальный идентификатор пользователя, дата и время голосования, а также все ответы. Предполагалось, что так каждый может проверить, что его ответы не были искажены.
Как выглядят результаты опросов на портале
Важную историю из этих данных можно было сделать только в том случае, если бы из них следовало, что голосования всё-таки проходят не очень честно. Например, в них участвует много ботов. Я стал смотреть, какие опросы доступны в виде открытых данных, и обнаружил ряд голосований с геопривязкой. Пользователей спрашивали, хорошо ли обустроили парк или улицу.
Моя первая гипотеза была такой: москвичи не будут принимать участие в опросах по разным частям города. Житель севера Москвы вряд ли что-то знает о том, что происходит на юге столицы. Если одни и те же люди ставят оценки благоустройству в далёких друг от друга местах, значит, с голосованиями что-то не так.
Я взял наугад два опроса (их результаты можно было загрузить с портала в формате xls) и решил совместить их. Для этого можно использовать, например, функцию ВПР в Excel. Но тогда у меня был ноутбук на Windows, а в PC-версии Excel можно быстро соединить несколько таблиц при помощи Power Query. Результат меня поразил — из ~200 тысяч участников каждого опроса более 100 тысяч поставили оценки благоустройству обоих мест. Мы стали исследовать данные более детально.
Как мы исследовали совпадающие голоса
Сначала я отсмотрел все названия опросов, результаты которых были выложены в виде открытых данных, и сохранил их к себе на компьютер. Мы также решили, что целесообразно исследовать только те улицы, которые находятся за пределами Садового кольца — москвичи всё-таки могут знать, что происходит в центре города.

Так мы определяли геопривязку
Получилось 10 таблиц, в которых я в дальнейшем стал искать совпадающие идентификаторы пользователей. Делать это в Excel было уже не очень удобно — нужно было сравнить каждое место с каждым. Поэтому для анализа я написал небольшой скрипт на Python с использованием библиотеки pandas, который обработал все эти таблички, и нашёл точное количество совпадающих пользователей для каждой пары опросов. Второй скрипт посчитал, сколько опросов прошёл каждый из пользователей.
Результаты анализа:
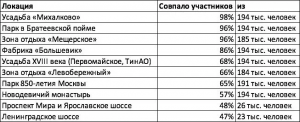
Как мы визуализировали результаты анализа
Следующий этап — визуализация. Визуализировать данные в те годы я умел на порядок хуже, поэтому задача показать, сколько процентов пользователей попарно совпадает в голосованиях, казалась мне крайне сложной. Это сейчас я понимаю, что нужно было использовать Heatmap, но на тот момент мы решили обойтись одной картой и таблицей, которые давали только часть информации.
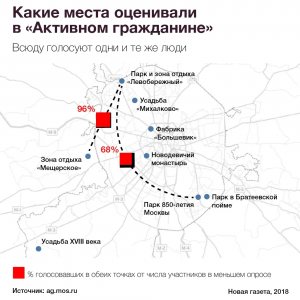
Карта иллюстрировала два показательных случая, а таблица давала информацию о совпадении участников опроса о благоустройстве парка «Левобережный» с другими опросами.
Изначально я думал соединить все точки на карте, а толщиной линии показать долю совпавших людей. Первый прототип визуализации в программе Nodebox выглядел устрашающе:
Из этой ситуации мне помог выйти мой педагог Денис Запорожан, который предложил прототип, близкий к финальной версии.
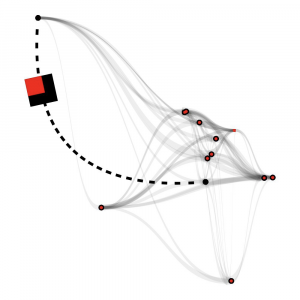
В процессе обсуждения работы мы пришли к выводу, что показывать имеет смысл не все точки сразу — а лишь несколько — для иллюстрации. Из прототипа, который предложил Денис, я взял только идею с квадратами, а карту в итоге построил в сервисе Tableau Public, доработав её внешний вид в Adobe Illustrator.
Все остальные графики в материале более простые, и они также выполнены при помощи Tableau и Illustrator.
Зачем москвичи проходят опросы, на которые не могут адекватно ответить? Ответ на этот вопрос лежит на поверхности прямо на сайте «Активного гражданина» — за голосования пользователям начисляют баллы, которые они могут потратить на приятные подарки — толстовки, зарядные устройства, проезд в метро или оплату парковки. Магазин поощрений богат на разнообразные призы. Подтверждение этому мы также нашли и в таблицах с опросами. Например, свободные поля москвичи заполняли так:
> Я думаю, что вы пи****сы
> Я не знаю что, я голосую ради баллов
Как мы пытались найти ботов в голосовании
У моего начальника, с которым мы делали материал, Андрея Заякина, была куда более радикальная гипотеза — активные граждане не только голосуют за всё подряд, но ещё и боты. Мы пытались проверить эту гипотезу двумя путями: Андрей — статистически анализируя открытые данные портала, а я — через проверку профилей в соцсетях.
Дело в том, что после прохождения опроса пользователи могут поделиться им с друзьями. Такие посты выглядят однотипно:
Российская социальная сеть ВКонтакте предоставляет разработчикам набор функций (API), благодаря которым можно выгружать информацию из соцсетей. Эти функции можно использовать с большинством языков программирования — я, например, использовал для работы Python.
С помощью функции newsfeed.search я получил 570 тысяч типовых постов, которые опубликовали 27 тысяч активных граждан. Для каждого автора я также выгрузил город проживания и родной город, которые были указаны в профиле. Абсолютное число проголосовавших, судя по сведениям соцсети, жило в Москве или в Московской области — это значит, что опросы проходили либо действительно москвичи (как и должно быть на московской платформе), либо слишком умело маскирующиеся под них люди.
У нас так и не получилось найти способ для автоматического определения ботов во ВКонтакте, поэтому несколько сотен случайных профилей я отсмотрел глазами. Ни один из этих профилей не вызвал у меня весомых подозрений, и мы пришли к выводу, что во ВКонтакте опросами «Активного гражданина» делились реальные люди.
Андрею удалось больше. Он исследовал два набора данных — подробные открытые данные о голосованиях, в которых я искал совпадающие голоса, а также данные о количестве голосов во всех опросах, которые были выложены на одной из страниц портала. Эти данные я соскрейпил при помощи скрипта на Python.
Сначала Андрей изучил несколько подробных датасетов с ответами пользователей. В частности, построил зависимость количества «позитивных» голосов в одном из опросов от даты голосования, и увидел, что получившаяся зависимость не похожа на естественную — вместо синусоиды график образует растущий тренд.
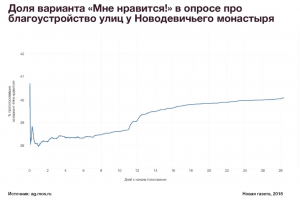
Данные о проголосовавших в каждом из опросов тоже оказались не похожими на естественное распределение — все опросы были либо очень интересными, либо никому не нужными, потому что вне зависимости от темы они набирали примерно равное количество голосов.
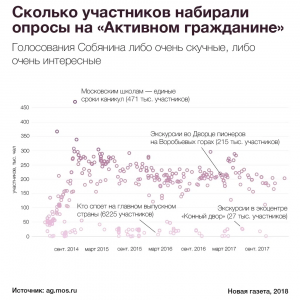
Наконец, Андрей сравнил популярность опросов на «Активном гражданине» с популярностью опросов на портале «Российская общественная инициатива». Голосам с РОИ можно доверять, поскольку пользователи там регистрируются с помощью портала «Госуслуги» и подтверждают личность с помощью документов — вероятность появления ботов на платформе крайне мала.
Распределение популярности опросов на РОИ похоже на реальное — большинство опросов никому не интересны — меньшая часть из них набирает хотя бы тысячу голосов. На «Активном гражданине» таких «неинтересных» голосований, напротив, оказалось мало.
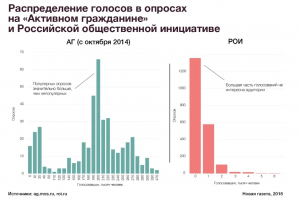
Впрочем, ни одно из доказательств не говорит явно о том, что на «Активном гражданине» голосуют боты — все из них лишь демонстрируют, что голосование протекало неестественным путём. Например, голоса могли «накручивать» бюджетники или проплаченные пользователи.
Что я думаю о нашей работе спустя три года
Это была одна из первых наших дата-работ, и на тот момент никто из нас не знал, как правильно выстроить рабочий процесс и сколько времени должно уходить на исследование. Тогда мы потратили на него три месяца (параллельно с другими проектами), и сейчас я думаю, что это очень много. Андрей настаивал, что бездумные голосующие — это недостаточно весомая тема для материала, поэтому мы долго выдумывали, как можно найти в голосовании ботов. В итоге это нам достоверно доказать не удалось.
Я также думаю, что не все визуализации в работе получились удачными — сейчас я бы сделал их куда более понятными.
Несмотря на все проблемы, я люблю эту работу, потому что в её основе лежит понятная идея, которую можно быстро объяснить и воспроизвести: соотнести два файла с геопривязкой, сравнить пользователей и обнаружить, что москвичи голосуют даже за то, чего не могут знать.
Данные, с которыми мы работали, я выложил в репозитории на GitHub, чтобы каждый мог проверить состоятельность наших выводов.