Извлечение данных (скрейпинг)
Короткое описание урока: этот урок научит вас конвертировать информацию в машиночитаемый формат.
Скрейпинг и техники извлечения данных позволяют создать таблицы из веб-страниц, PDF-документов или других немашиночитаемых форматов.
В этом уроке мы извлечем таблицу из PDF-документа.

Извлечение данных с помощью программы Табула
Табула – это программа для извлечения табличных данных из PDF файлов. Это очень удобный инструмент для большинства таких случаев. Программа открывается у вас в браузере, но использует локальное соединение – это значит, что при использовании Табулы интернет не нужен.
Установка Табулы
- Убедитесь, что у вас на компьютере установлена Java, если у вас Windows. Ее можно загрузить по этой ссылке. Для MacOS этого не требуется.
- Зайдите на официальный вебсайт Табулы.
- Загрузите ту версию Табулы, которая подходит для вашей операционной системы.
- На ваш компьютер начнет загружаться зип файл. Извлеките архив – вы получите папку «tabula».
- Откройте эту папку и установите программу. Должно появиться всплывающее окно с кодом – это означает, что начался процесс установки.
- После этого откроется окно веб-браузера. Это и есть Табула. Если браузер не открывается, наберите сами следующий адрес: http://127.0.0.1:8080
Так выглядит Табула в браузере:
Пользуемся Табулой
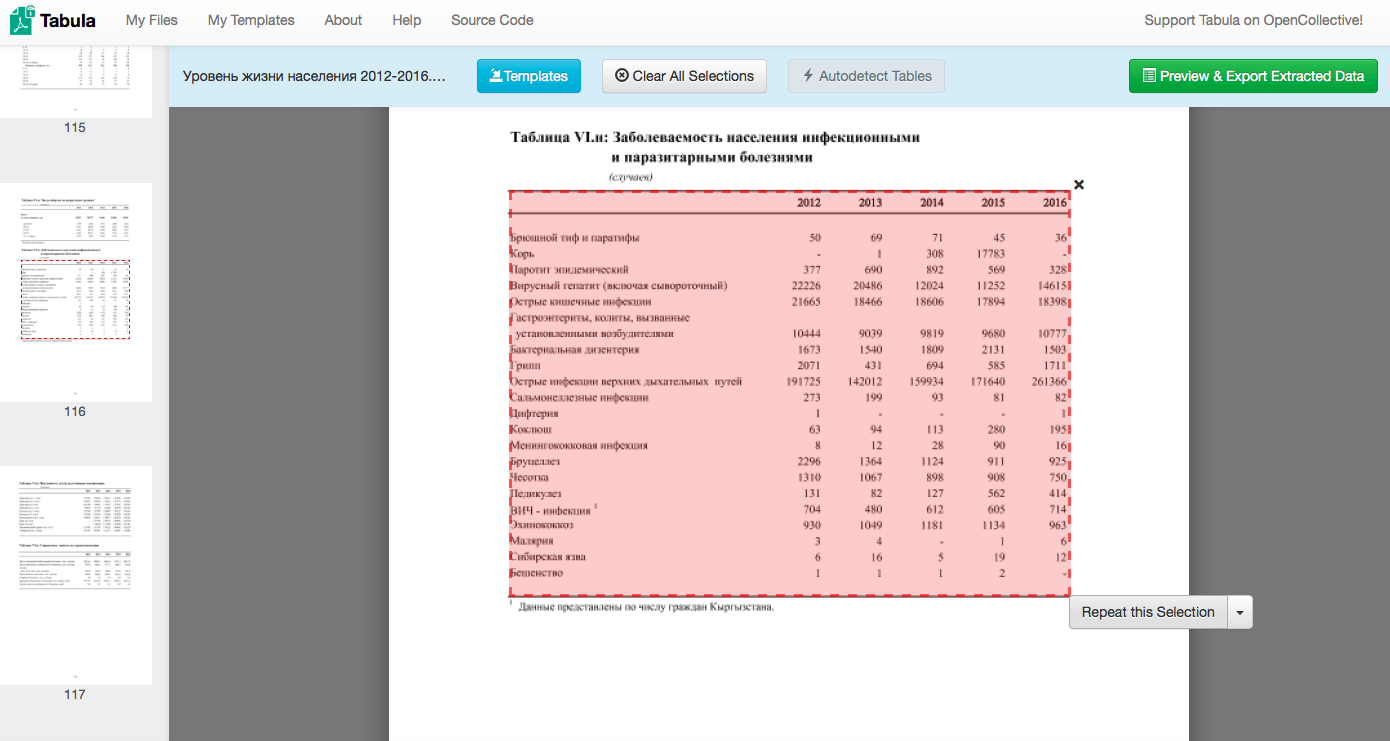
Давайте воспользуемся Табулой, чтобы извлечь одну из таблиц из годовой публикации Нацстаткома «Уровень жизни населения Кыргызской Республики 2012-2016». Для начала найдите страницу 114 в публикации и таблицу “Таблица VI.н: Заболеваемость населения инфекционными и паразитарными болезнями”.
Давайте извлечем ее в табличный формат.
- Когда Табула откроется у вас в браузере, нажмите кнопку Browse и найдите файл с публикацией.
- Теперь нажмите Import. Это займет некоторое время, так как Табула будет подгружать весь файл. Наконец, вам будет доступно превью файла.
- Когда документ загрузится, прокрутите его до страницы 114, чтобы найти нужную вам таблицу.
- Табула позволяет вам выбрать нужные таблицы внутри документа. Вы можете использовать функцию “Autoselect tables” для выделения всех таблиц, но при работе с большими документами лучше этого не делать. Вы всегда видите, что именно вы выбрали: эта область будет выделена красным. Выбор можно скорректировать, потянув за угол выбранной области. Функция ‘Clear all selections’ снимает все выделения.
- Выберите таблицу “Таблица VI.н: Заболеваемость населения инфекционными и паразитарными болезнями”.
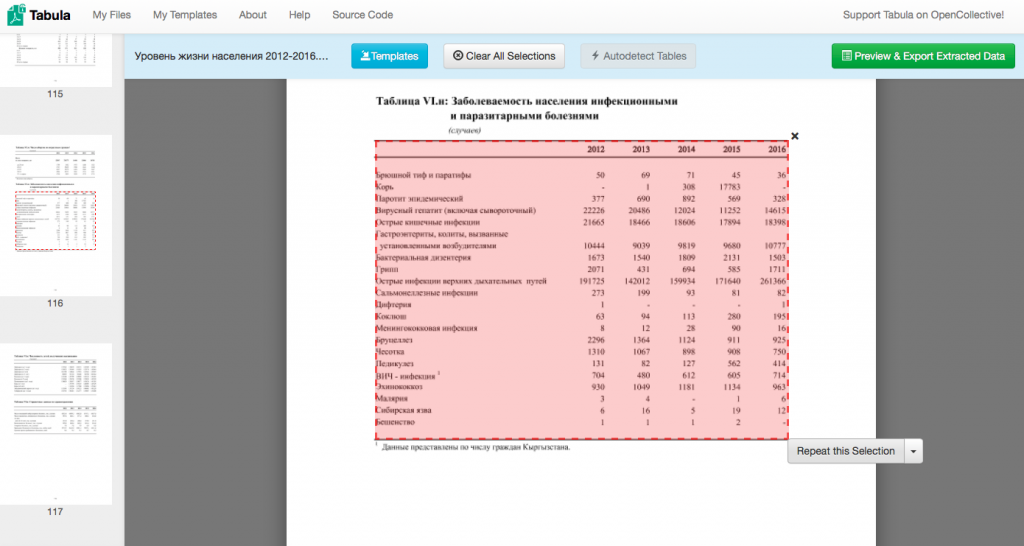
- Важный момент: надо выделить всю таблицу так, чтобы выделенная область не включала в себя элементы, которые к таблице не относятся. Табула умеет распознавать табличные структуры в файлах pdf, и значит, выделять нужно только то, что внутри таблицы. В то же время важно не отрезать крайние ряды. Вы сможете сами это проверить через секунду.
- Нажмите Preview & Export Extracted Data.
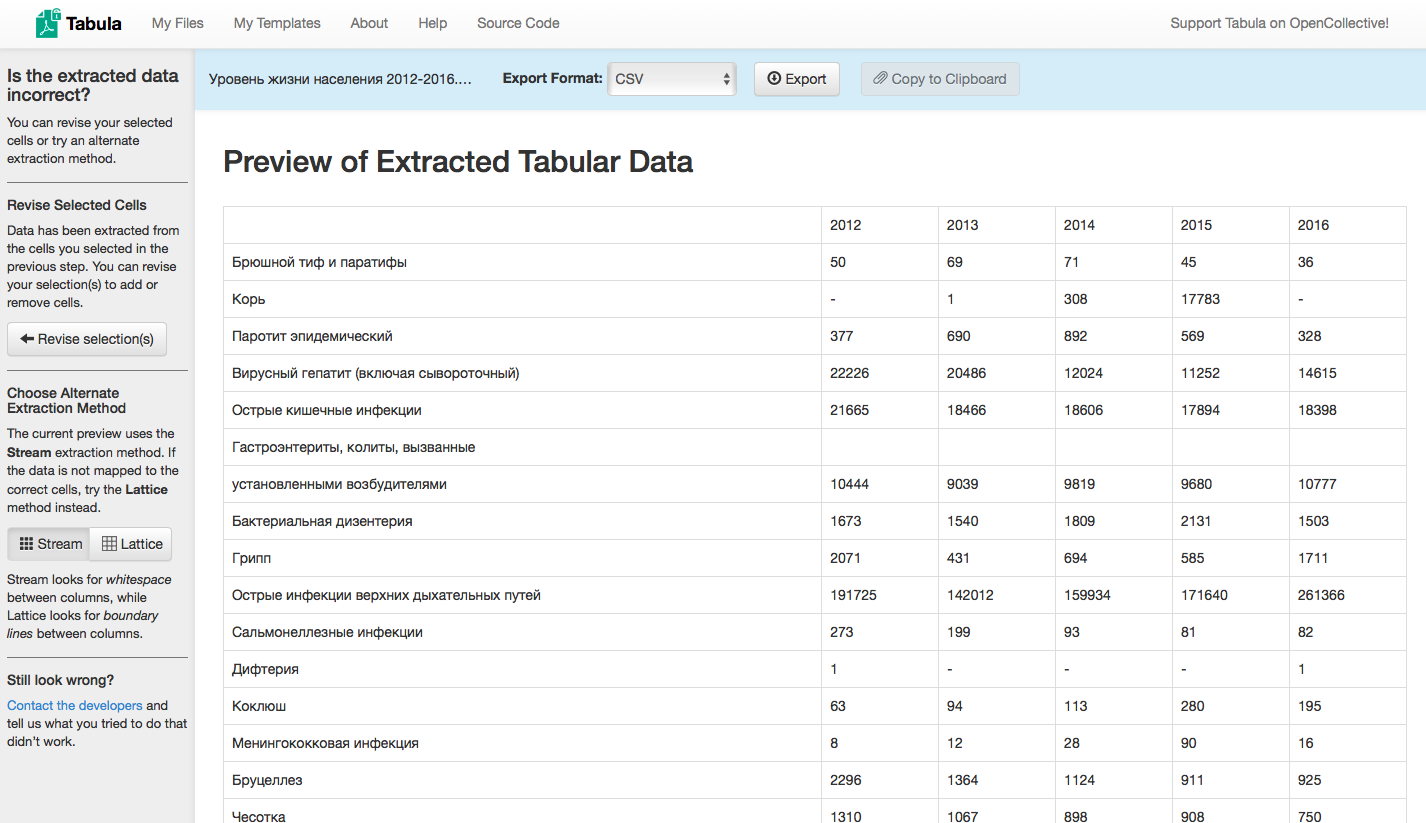
- Появится следующее окно, в котором вы увидите превью извлеченных данных в структурированном, машиночитаемом виде. Проверьте, правильно ли выглядит эта таблица. Если чего-то не хватает, вернитесь назад и измените выделение.
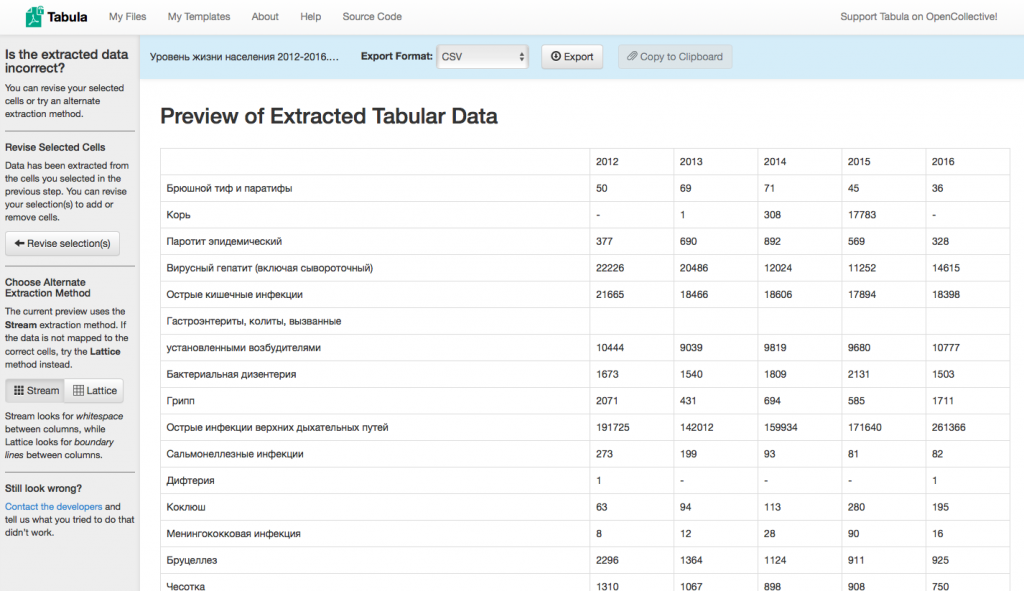
- Иногда заголовки отформатированы внутри таблицы в формате pdf таким образом, что когда мы их выделяем, Табула теряет структуру таблицы. В таких случаях, надо выделить таблицу без заголовков, а затем допечатать их вручную.
- Другой путь исправить вид извлеченных данных – поменять метод извлечения. Как вы видите из меню слева, есть два метода извлечения, Stream и Lattice. Stream ориентируется на пустые промежутки между данными, а Lattice – на границы ячеек. Попробуйте поменять метод извлечения, если вы не до конца довольны результатом.
- Наконец, когда таблица извлечена правильно, экспортируйте файл в формате CSV c помощью функции Export.
- Теперь с этими данными можно работать в табличной программе вроде Excel. Но сперва нам нужно импортировать CSV: об этом в следующем уроке.